Risk Measures
Quickstart
outcomes = rand(100)
# direct usage
VaR(0.90)(outcomes) # ≈ 0.90
CTE(0.90)(outcomes) # ≈ 0.95
WangTransform(0.90)(outcomes) # ≈ 0.81
# construct a reusable object (functor)
rm = VaR(0.90)
rm(outcomes) # ≈ 0.90Introduction
Risk measures encompass the set of functions that map a set of outcomes to an output value characterizing the associated riskiness of those outcomes. As is usual when attempting to compress information (e.g. condensing information into a single value), there are multiple ways we can characterize this riskiness.
Coherence & Other Desirable Properties
Further, it is desirable that a risk measure has certain properties, and risk measures that meet the first four criteria are called "Coherent" in the literature. From "An Introduction to Risk Measures for Actuarial Applications" (Hardy), she describes as follows:
Using $H$ as a risk measure and $X$ as the associated risk distribution:
1. Translation Invariance
For any non-random $c$
\[H(X + c) = H(X) + c\]
This means that adding a constant amount (positive or negative) to a risk adds the same amount to the risk measure. It also implies that the risk measure for a non-random loss, with known value c, say, is just the amount of the loss c.
2. Positive Homogeneity
For any non-random $λ > 0$:
\[H(λX) = λH(X)\]
This axiom implies that changing the units of loss does not change the risk measure.
3. Subadditivity
For any two random losses $X$ and $Y$,
\[H(X + Y) ≤ H(X) + H(Y)\]
It should not be possible to reduce the economic capital required (or the appropriate premium) for a risk by splitting it into constituent parts. Or, in other words, diversification (ie consolidating risks) cannot make the risk greater, but it might make the risk smaller if the risks are less than perfectly correlated.
4. Monotonicity
If $Pr(X ≤ Y) = 1$ then $H(X) ≤ H(Y)$.
If one risk is always bigger then another, the risk measures should be similarly ordered.
Other Properties
In "Properties of Distortion Risk Measures" (Balbás, Garrido, Mayoral) also note other properties of interest:
Complete
Completeness is the property that the distortion function associated with the risk measure produces a unique mapping between the original risk's survival function $S(x)$ and the distorted $S*(x)$ for each $x$. See Distortion Risk Measures for more detail on this.
In practice, this means that a non-complete risk measure ignores some part of the risk distribution (e.g. CTE and VaR do not use the full distribution, so two risks that differ only outside the measured tail can produce the same value of the risk measure).
Exhaustive
A risk measure is "exhaustive" if it is coherent and complete.
Adaptable
A risk measure is "adapted" or "adaptable" if its distortion function (see Distortion Risk Measures) $g$ satisfies:
\[g\]
is strictly concave, that is, $g^\prime$ is strictly decreasing.\[\lim_{u\to 0^+} g^\prime(u) = \infty\]
and $\lim_{u\to 1^-} g^\prime(u) = 0$.
Adaptive risk measures are exhaustive but the converse is not true.
Summary of Risk Measure Properties
| Measure | Coherent | Complete | Exhaustive | Adaptable | Condition 2 |
|---|---|---|---|---|---|
| VaR | No | No | No | No | No |
| CTE | Yes | No | No | No | No |
| DualPower $(y > 1)$ | Yes | Yes | Yes | No | Yes |
| ProportionalHazard $(γ > 1)$ | Yes | Yes | Yes | No | Yes |
| WangTransform | Yes | Yes | Yes | Yes | Yes |
Distortion Risk Measures
Distortion Risk Measures (Wikipedia Link) are a way of remapping the probabilities of a risk distribution in order to compute a risk measure $H$ on the risk distribution $X$.
Adapting Wang (2002), there are two key components:
Distortion Function $g(u)$
This remaps values in the [0,1] range to another value in the [0,1] range, and in $H$ below, operates on the survival function $S$ and $F=1-S$.
Let $g:[0,1]\to[0,1]$ be an increasing function with $g(0)=0$ and $g(1)=1$. The transform $F^*(x)=g(F(x))$ defines a distorted probability distribution, where "$g$" is called a distortion function.
Note that $F^*$ and $F$ are equivalent probability measures if and only if $g:[0,1]\to[0,1]$ is continuous and one-to-one. Definition 4.2. We define a family of distortion risk-measures using the mean-value under the distorted probability $F^*(x)=g(F(x))$:
Risk Measure Integration
To calculate a risk measure $H$, we integrate the distorted $F$ across all possible values in the risk distribution (i.e. $x \in X$):
\[H(X) = E^*(X) = - \int_{-\infty}^0 g(F(x))dx + \int_0^{+\infty}[1-g(F(x))]dx\]
That is, the risk measure ($H$) is equal to the expected value of the distortion of the risk distribution ($E^*(X)$).
When risk is a continuous Distributions.jl distribution, this integral is evaluated by numerical quadrature of the distorted distribution function. When risk is an array of outcomes, the same Choquet integral reduces to a finite weighted sum of the sample's order statistics, and VaR, CTE, and Expectation evaluate that sum exactly (no quadrature or approximation error); the other distortion measures integrate the distorted empirical CDF numerically.
Examples
Basic Usage
outcomes = rand(100)
# direct usage
VaR(0.90)(outcomes) # ≈ 0.90
CTE(0.90)(outcomes) # ≈ 0.95
WangTransform(0.90)(outcomes) # ≈ 0.81
# construct a reusable object (functor)
rm = VaR(0.90)
rm(outcomes) # ≈ 0.90Comparison
We will generate a random outcome and show how the risk measures behave:
using Distributions
using ActuaryUtilities
using CairoMakie
outcomes = Weibull(1,5)
# or this could be discrete outcomes as in the next line
#outcomes = rand(LogNormal(2,10)*100,2000)
αs= range(0.00,0.99;length=100)
let
f = Figure()
ax = Axis(f[1,1],
xlabel="α",
ylabel="Loss",
title = "Comparison of Risk Measures",
xgridvisible=false,
ygridvisible=false,
)
lines!(ax,
αs,
[quantile(outcomes, α) for α in αs],
label = "Quantile α of Outcome",
color = :grey10,
linewidth = 3,
)
lines!(ax,
αs,
[VaR(α)(outcomes) for α in αs],
label = "VaR(α)",
linestyle=:dash
)
lines!(ax,
αs,
[CTE(α)(outcomes) for α in αs],
label = "CTE(α)",
)
lines!(ax,
αs[2:end],
[WangTransform(α)(outcomes) for α in αs[2:end]],
label = "WangTransform(α)",
)
lines!(ax,
αs,
[ProportionalHazard(2)(outcomes) for α in αs],
label = "ProportionalHazard(2)",
)
lines!(ax,
αs,
[DualPower(2)(outcomes) for α in αs],
label = "DualPower(2)",
)
lines!(ax,
αs,
[Expectation()(outcomes) for α in αs],
label = "Expectation",
)
axislegend(ax,position=:lt)
f
end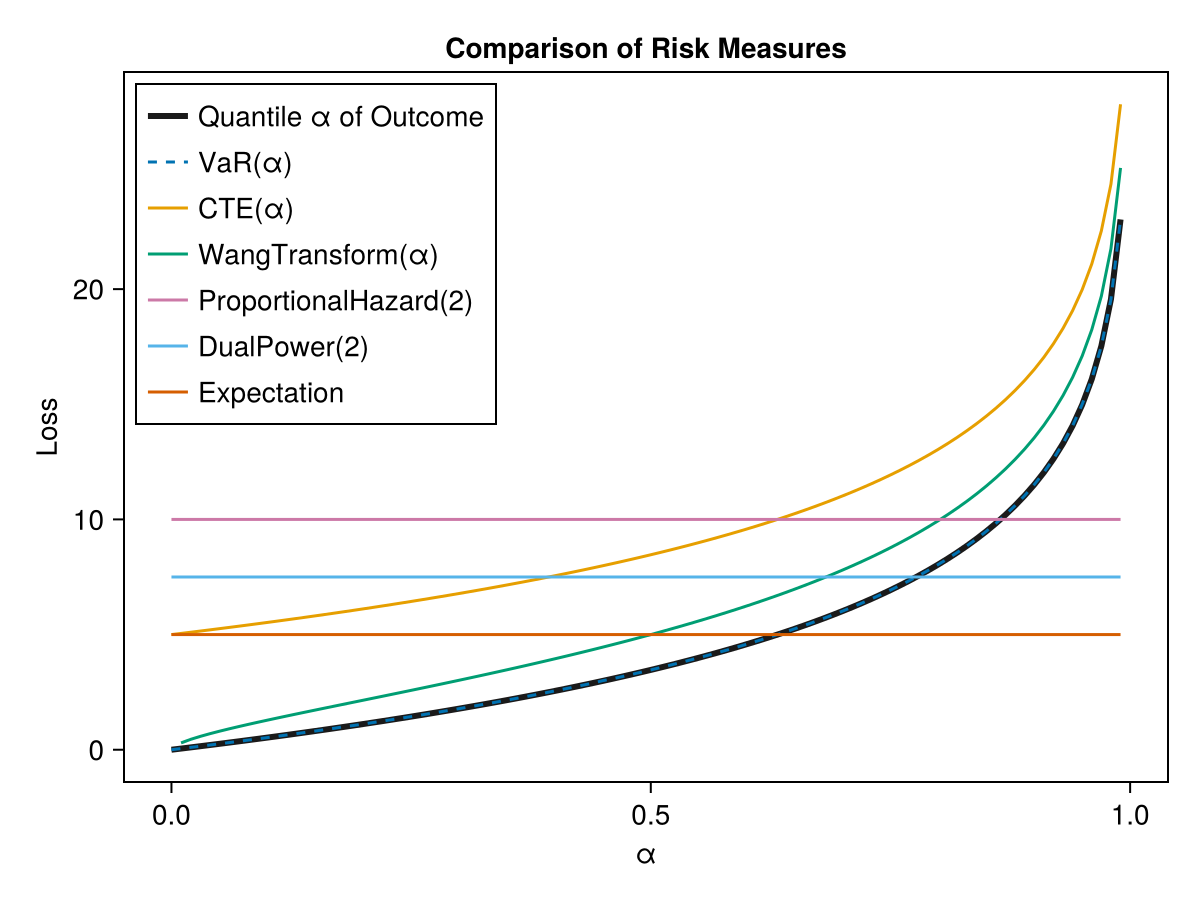
API
Exported API
ActuaryUtilities.RiskMeasures.CTE — Type
CTE(α)::RiskMeasure
CTE(α)(risk)::T (where T is the type of values sampled in risk)The Conditional Tail Expectation (CTE) at level α is the expected value of the risk distribution above the αth quantile. risk can be a univariate distribution or an array of outcomes. Assumes more positive values are higher risk measures, so a higher p will return a more positive number.
CTE(α) returns a functor which can then be called on a risk distribution.
Parameters
- α: [0,1.0)
Examples
julia> CTE(0.95)(rand(1000))
0.9766218612020593
julia> rm = CTE(0.95)
CTE{Float64}(0.95)
julia> rm(rand(1000))
0.9739835010268733ActuaryUtilities.RiskMeasures.DualPower — Type
DualPower(v)::RiskMeasure
DualPower(v)(risk)::T (where T is the type of values sampled in risk)The Dual Power distortion risk measure is defined as $1 - (1 - x)^v$, where x is the cumulative distribution function (CDF) of the risk distribution and v is a positive parameter. risk can be a univariate distribution or an array of outcomes.
DualPower(v) returns a functor which can then be called on a risk distribution.
ActuaryUtilities.RiskMeasures.Expectation — Type
Expectation()::RiskMeasure
Expectation()(risk)::T (where T is the type of values sampled in `risk`)The expected value of the risk.
Expectation() returns a functor which can then be called on a risk distribution.
Examples
julia> Expectation()(rand(1000))
0.4793223308812537
julia> rm = Expectation()
ActuaryUtilities.RiskMeasures.Expectation()
julia> rm(rand(1000))
0.4941708036889741ActuaryUtilities.RiskMeasures.ProportionalHazard — Type
ProportionalHazard(y)::RiskMeasure
ProportionalHazard(y)(risk)::T (where T is the type of values sampled in risk)The Proportional Hazard distortion risk measure is defined as $x^(1/y)$, where x is the cumulative distribution function (CDF) of the risk distribution and y is a positive parameter. risk can be a univariate distribution or an array of outcomes. ProportionalHazard(y) returns a functor which can then be called on a risk distribution.
Examples
julia> ProportionalHazard(2)(rand(1000))
0.6659603556774121
julia> rm = ProportionalHazard(2)
ProportionalHazard{Int64}(2)
julia> rm(rand(1000))
0.6710587338367799ActuaryUtilities.RiskMeasures.VaR — Type
VaR(α)::RiskMeasure
VaR(α)(risk)::T (where T is the type of values sampled in `risk`)The αth quantile of the risk distribution is the Value at Risk, or αth quantile. risk can be a univariate distribution or an array of outcomes. Assumes more positive values are higher risk measures, so a higher p will return a more positive number. For a discrete risk, the VaR returned is the first value above the αth percentile.
VaR(α) returns a functor which can then be called on a risk distribution.
Parameters
- α: [0,1.0)
Examples
julia> VaR(0.95)(rand(1000))
0.9561843082268024
julia> rm = VaR(0.95)
VaR{Float64}(0.95)
julia> rm(rand(1000))
0.9597070153670079ActuaryUtilities.RiskMeasures.WangTransform — Type
WangTransform(α)::RiskMeasure
WangTransform(α)(risk)::T (where T is the type of values sampled in risk)The Wang Transform is a distortion risk measure that transforms the cumulative distribution function (CDF) of the risk distribution using a normal distribution with mean Φ⁻¹(α) and standard deviation 1. risk can be a univariate distribution or an array of outcomes.
WangTransform(α) returns a functor which can then be called on a risk distribution.
Parameters
- α: [0,1.0]
In the literature, sometimes λ is used where $\lambda = \Phi^{-1}(\alpha)$.
Examples
julia> WangTransform(0.95)(rand(1000))
0.8799465543360105
julia> rm = WangTransform(0.95)
WangTransform{Float64}(0.95)
julia> rm(rand(1000))
0.8892245759705852References
- "A Risk Measure That Goes Beyond Coherence", Shaun S. Wang, 2002
Unexported API
ActuaryUtilities.RiskMeasures.cdf_func — Method
cdf_func(risk)Returns the appropriate cumulative distribution function depending on the type, specifically:
cdf_func(S::AbstractArray{<:Real}) = StatsBase.ecdf(S)
cdf_func(S::Distributions.UnivariateDistribution) = x -> Distributions.cdf(S, x)ActuaryUtilities.RiskMeasures.g — Method
g(rm::RiskMeasure,x)The probability distortion function associated with the given risk measure.